crewAI 如何实现 agent 自主互相调用🤖
本文预设读者对 AI agent, function-call, tool use 等概念有一定了解.
crewAI 的一个突出特点是基于角色的 agent 设计, 允许用户自定义具有特定角色, 目标和工具的 agent.
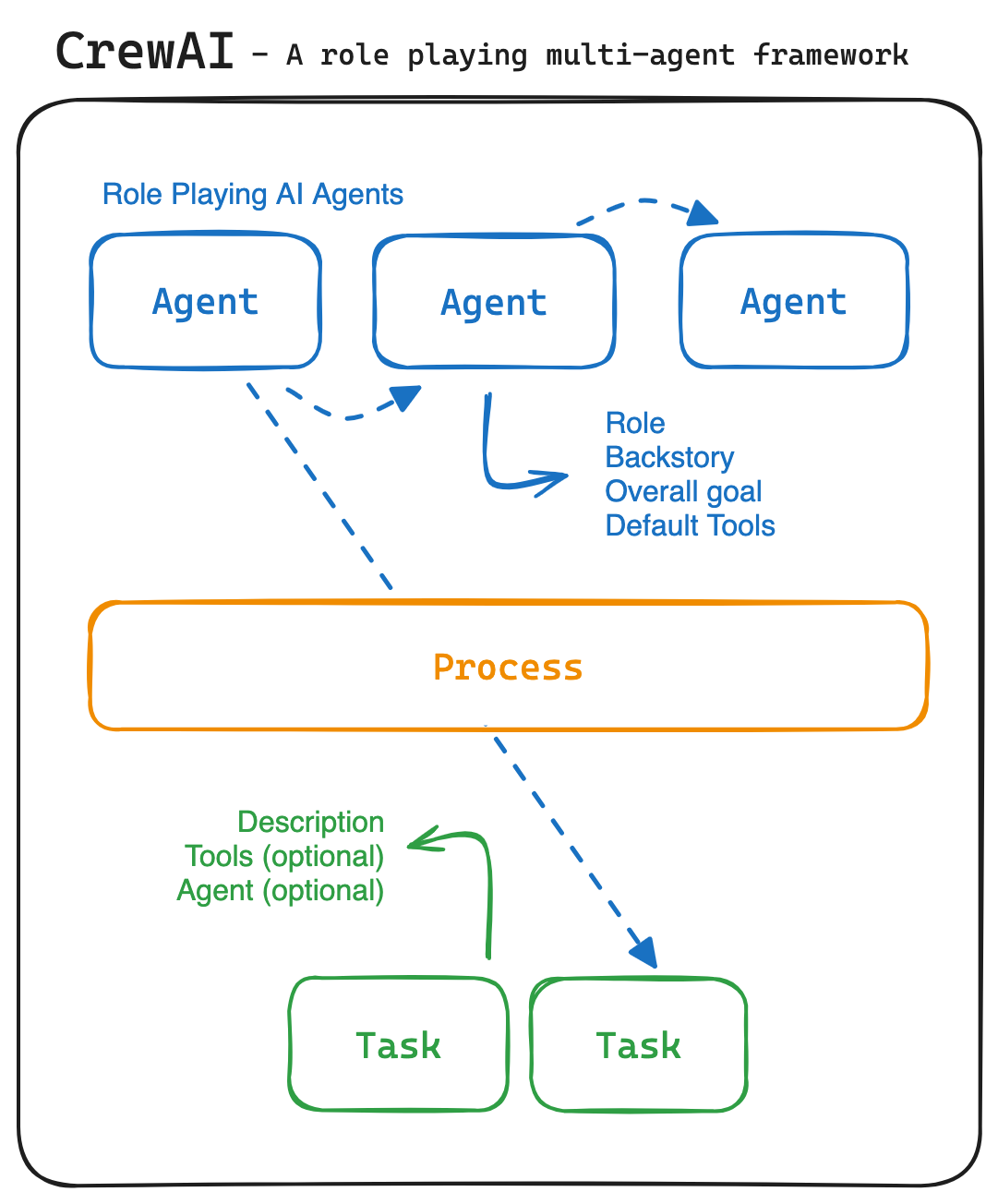 crewAI 的 agent 之间可以自主委派任务, 不要求明确指示. 和要求显式定义执行步骤的框架 ( e.g. LangChain ) 相比, 灵活性更好. 接下来让我们看看这些特性是如何实现的.
crewAI 的 agent 之间可以自主委派任务, 不要求明确指示. 和要求显式定义执行步骤的框架 ( e.g. LangChain ) 相比, 灵活性更好. 接下来让我们看看这些特性是如何实现的.
核心概念 & 实现
Crew 是一个容器, 包含了一组需要完成的 tasks, 参与任务的 agents, 和可以使用的 tools.
crew = Crew(
tasks=[...],
agents=[researcher, writer],
manager_llm=ChatOpenAI(temperature=0, model="gpt-4"),
process=Process.hierarchical,
)
process 有两个选项, sequential 对应任务顺序执行, 每个 task 在创建的时候需要指定一个 agent 来完成;
选择 hierarchical, 任务由一个 manager agent 进行调度, 指派其他 agent 来执行.
Agent 主要封装 LLM 调用, 底层使用的 LangChain. 调用 LLM 的 prompt 由 task, tool 等几部分拼接组成
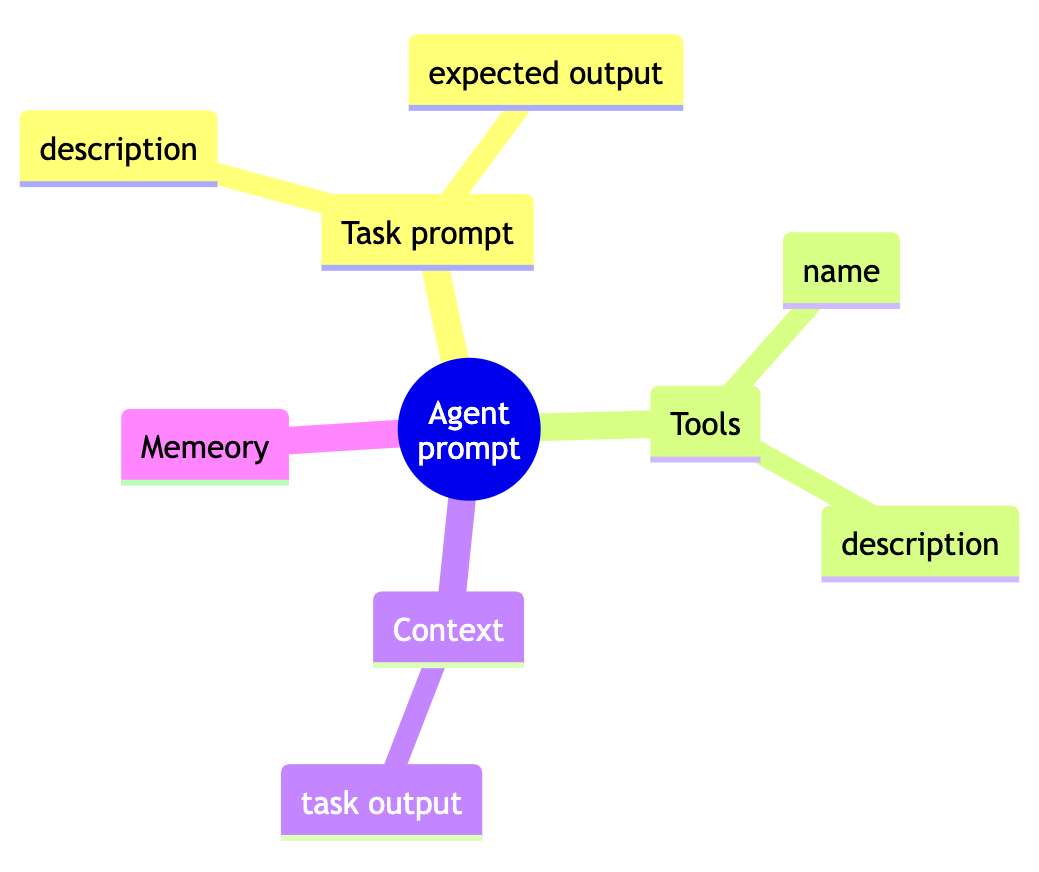
开始执行后, agent 使用 ReAct 方式与 LLM 交互直至任务完成 (或者超过交互次数限制).
Task Delegation
crewAI 有个有趣的特性, 就是 agent 可以将任务委派给其他 agent, 就像人类上班时和同事配合完成工作. 委派任务有两种形式:
- ask_question: 向 coworker (其他 agent ) 提问, 返回 coworker 的输出
- delegate_work: 让 coworker 直接执行 task
实现方式是将 agent 封装成 tool, 这样就可以通过 ReAct 方式被模型调用
tools = [
StructuredTool.from_function(
func=self.delegate_work,
name="Delegate work to co-worker",
description=self.i18n.tools("delegate_work").format(
coworkers=f"[{', '.join([f'{agent.role}' for agent in self.agents])}]"
),
),
# omitted for clarity ...
]
agent 当作 tool 使用时对应的 description
Delegate a specific task to one of the following co-workers: {coworkers}
The input to this tool should be the co-worker, the task you want them to do, and ALL necessary context to execute the task, they know nothing about the task, so share absolute everything you know, don't reference things but instead explain them.
效果评估
crewAI 主要使用方式是通过 Python 代码调用, 执行过程有详细日志输出到 terminal, 绿色代表 agent 的 “思考” 过程, 紫色代表 task 的最终结果. 在使用过程也发现了几个问题.
1. 使用 tool 时, 因为选择参数错误导致多次调用
看源码 tool 调用功能是直接引用的 LangChain, tool 的参数列表是通过 Python object __annotations__ 拼接的, e.g. 搜索工具的参数列表:
>>> DuckDuckGoSearchRun._run.__annotations__
{'query': <class 'str'>, 'run_manager': typing.Optional[langchain_core.callbacks.manager.CallbackManagerForToolRun], 'return': <class 'str'>}
这个实现很方便, 但是里面包含了较多无用信息, 会干扰能力不够强的模型. agent 尝试几次以后可能会猜对参数, 但是下次调用又要重新猜. 这里优化方式可以考虑调用成功以后, 把本次调用方式缓存起来.
2. task delegation 偶现找不到指定 agent
crewAI 的实现中, 会使用 agent role 作为 tool name, 而 role 一般会使用角色身份一类的短语. LLM 在选定 tool 以后, 输出中包含的 tool name 可能因为大小写, 或者空白字符等问题, 无法完全匹配 agent role, 进而导致 agent 不存在的报错. 这里可以使用更宽松的匹配方式, 引入模糊匹配和编辑距离等优化方式.
3. agent 不必要 LLM 调用开销
处理多跳 ( multiple-hop) 问题时, agent 需要多次执行 web search, 和 LLM 多次交互. e.g. 回答鲍勃马利出生地使用什么货币, 需要先知道鲍勃马利是谁在哪国出生, 那里的法定货币是什么. 用 crewAI 处理多跳问题一个常见的现象是, 第一次的 web search 返回的结果其实已经包含了足够的信息, agent 仍然决定继续追踪搜索返回的各个 url. 这些页面的文本最终都会经由 LLM 处理, 浪费时间和 token.
结论
crewAI 诞生于 agent 理念被广泛关注以后, 在 agent framework 领域新的产品往往有后发优势, crewAI 使用非常简单, 它很受欢迎并不意外.
 仔细观察会发现和同类产品相比, crewAI 并没有带来本质变化 – 稳定性, 确定性和 task 完成效果依然主要仰赖 LLM 的能力, 框架自身没有带来多少优化.
仔细观察会发现和同类产品相比, crewAI 并没有带来本质变化 – 稳定性, 确定性和 task 完成效果依然主要仰赖 LLM 的能力, 框架自身没有带来多少优化.