理解 broadcasting 📢
broadcasting 本质是让大小不相同的两个 tensor 拉抻后具有相同的大小, 能够进行数学运算
问题
tensor 进行逐个元素计算时, 通常要求二者 shape 要匹配
a = tensor([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
b = tensor([[0, 1, 2],
[0, 1, 2],
[0, 1, 2],
[0, 1, 2]])
a * b
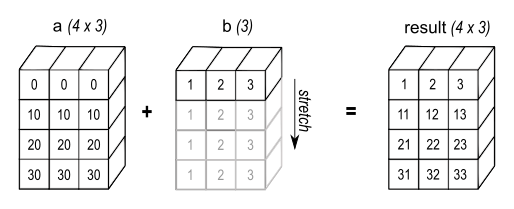
如果二者形状不同呢? 可以遍历 row / col 计算并组装结果
c = torch.zeros(a.shape)
ar, ac = a.shape
for i in range(ar):
c[i] = a[i] * b
但这样很慢: Python 的 loop 是 python 实现的, 效率远低于 C 实现的 tensor 运算. 所以需要一个方法, 把 b 拉伸成 a 一样的形状
broadcast 规则
两个大小 (len(a.shape), 或者 t.ndim) 不相同的 tensor 进行计算时, 可以把较小的一方拉伸成与较大的相同
对于 a, b 两 个tensor, 拉伸按照以下规则进行:
- 从最后一个 dim 开始逐个比较
- 二者的 size 相同的话不需要拉伸, 继续比较前一个
- a 的 dim 不存在, 或者 size = 1, 则 a 在这个 dim 上进行 “复制”
- …… 直到所有 dim 处理完
举几个例子
A, B, C, D 形状如下: A: 5 x 1 B: 1 x 6 C: 6 D: 1 C 是有 6 个元素的 vector, D 是 scalar 通过 broadcasting 进行运算
A (rank 2 tensor): 5 x 1
B (rank 2 tensor): 1 x 6
Result (rank 2 tensor): 5 x 6
A 的第一列 a[:, 0] 在 x 轴 (dim 0) 方向上复制 6 次, A 表现为 5 x 6
B 的第一行 b[0, :] 在 y 轴方向上复制 5 次
B (rank 2 tensor): 1 x 6
C (rank 1 tensor): 6
Result (rank 2 tensor): 1 x 6
C 与 B 最后一个 dim 相同, C 补上缺少的 dim, 表现为 1 x 6
A (rank 2 tensor): 5 x 1
D (scalar ): 1
Result (rank 2 tensor): 5 x 1
D 的唯一一个元素在每一个位置上复制, D 表现为 5 x 1
broadcasting 实现
将较小的 tensor 复制多份以便较大的进行匹配, 在处理很大的 tensor 运算时会消耗很多时间和内存, broadcasting 的实现很聪明, 并不会复制数据
tesnor.expand_as 将 b 拉伸到与 a 大小相同, 和 broadcasting 里一样
b = b.expand_as(a)
b.shape, b
# Output:
(torch.Size([4, 3]),
tensor([[0, 1, 2],
[0, 1, 2],
[0, 1, 2],
[0, 1, 2]]))
但是实际上 b 的底层数据没有复制
b.storage()
# Output:
0
1
2
[torch.storage.TypedStorage(dtype=torch.int64, device=cpu) of size 3]
秘密就在于控制在各个 dim (axis) 上移动的步长 (stride)
b.stride(), b.shape
# Output:
((0, 1), torch.Size([4, 3]))
想象有一个 cursor 在 b 的 row 上移动, 当需要移动到下一个 row 时, 因为 tride = 0, cursor 位置不会发生变化